


Модуль сбора и воспроизведения данных
Модуль сбора и воспроизведения данных – тема, с которой мы сталкиваемся практически в каждой нашей работе в ООО Сиань Чэнань Измерение и Контроль Технологии. Иронично, но часто возникает ощущение, что это просто 'черный ящик', который должен работать. Многие компании, особенно на начальных этапах, подходят к разработке сбора данных как к механической задаче – просто собрать показания, сохранить и вернуть. Но на практике всё гораздо сложнее. Настоящий модуль сбора и воспроизведения данных должен быть гибким, адаптивным и, самое главное, обеспечивать достоверность информации. И не просто собирать, а именно *воспроизводить* – то есть, иметь возможность повторно использовать собранные данные для анализа, отладки или даже для калибровки последующих измерений.
Проблема целостности данных: от датчика до хранилища
Первое, что обычно приходит в голову – выбор подходящего датчика. Но это лишь вершина айсберга. Нам часто приходится сталкиваться с проблемами, возникающими на уровне аналого-цифрового преобразователя (АЦП) и последующей обработки данных. Особенно когда речь заходит о сложных системах, работающих в условиях повышенного электромагнитного шума. Мы неоднократно сталкивались с ситуациями, когда 'правильные' данные измерялись при одной конфигурации АЦП, а при незначительном изменении параметров, например, напряжения питания или температуры, результат существенно отличался. Это, конечно, неприемлемо для критически важных приложений.
Важно понимать, что не стоит рассматривать АЦП как 'черный ящик'. Каждый АЦП имеет свои ограничения и особенности, которые необходимо учитывать при проектировании системы сбора данных. Мы часто используем специализированные АЦП с высоким разрешением и низким уровнем шума, но даже в этом случае требуется тщательная калибровка и компенсация дрейфа. Кроме того, не стоит забывать о программном обеспечении, которое обрабатывает данные. Алгоритмы фильтрации, компенсации и преобразования могут существенно повлиять на достоверность результатов. К сожалению, нередко видим ситуации, когда разработчики уделяют недостаточно внимания именно программной части, и в итоге получают данные, которые не соответствуют действительности. Поэтому в нашем случае всегда начинаем с детального анализа схемы сбора и обработки данных, а затем переходим к выбору конкретных компонентов.
Как мы решаем проблемы шума и дрейфа?
Для решения проблем, связанных с шумом и дрейфом, мы часто используем методы цифровой фильтрации, такие как скользящее среднее, медианный фильтр и Kalman filter. Также мы применяем специальные алгоритмы калибровки, которые позволяют компенсировать изменения параметров АЦП и других компонентов системы.
Но в некоторых случаях, программные методы не справляются с задачей. В этих случаях мы используем аппаратные решения, такие как экранирование, заземление и демпфирование вибраций. Мы также используем специальные фильтры, которые блокируют нежелательные частоты шума.
Важно помнить, что решение проблем шума и дрейфа – это сложный и многогранный процесс, который требует глубоких знаний и опыта. Не существует универсального решения, и каждый случай требует индивидуального подхода.
Реализация модулей: от прототипа до готового решения
Создание полноценного модуля сбора и воспроизведения данных – это не просто сборка компонентов. Это комплексная задача, которая включает в себя проектирование аппаратной и программной частей, тестирование, отладку и интеграцию с другими системами. Мы используем различные микроконтроллеры, от простых моделей, таких как Arduino, до более мощных плат, основанных на ARM Cortex-M. Выбор микроконтроллера зависит от требований к производительности, энергопотреблению и объему памяти.
В качестве программного обеспечения мы часто используем C/C++ и Python. C/C++ подходит для реализации низкоуровневых алгоритмов, таких как работа с АЦП и таймерами. Python подходит для реализации высокоуровневых алгоритмов, таких как обработка данных и визуализация. Мы также используем различные библиотеки и фреймворки, такие как FreeRTOS, STM32 HAL и NumPy.
Пример из практики: система мониторинга параметров окружающей среды
Недавно мы разработали систему мониторинга параметров окружающей среды, которая должна была использоваться для контроля качества воздуха в помещении. Система состояла из нескольких датчиков, измеряющих температуру, влажность, концентрацию углекислого газа и других газов. Данные собирались с помощью микроконтроллера STM32F4 и передавались по беспроводной сети на сервер для хранения и анализа. Для реализации системы мы использовали C/C++ для написания драйверов датчиков и алгоритмов обработки данных, а также Python для создания веб-интерфейса для визуализации данных.
Одним из самых сложных моментов разработки системы была калибровка датчиков. Мы использовали метод линейной регрессии для компенсации дрейфа датчиков и повышения точности измерений. Также мы реализовали алгоритм фильтрации, который позволял удалять шум из данных. В результате мы получили систему, которая обеспечивает точные и надежные измерения параметров окружающей среды.
Но были и ошибки. Сначала мы не учли влияние электромагнитных помех на показания датчика CO2. Это потребовало доработки схемы экранирования и добавления фильтров. Это показывает, что даже при тщательном проектировании могут возникать непредвиденные проблемы, и важно быть готовым к ним.
Воспроизведение данных: возможность анализа и повторного использования
И вот мы добрались до самого интересного – воспроизведения данных. В большинстве случаев, сбор данных – это одноразовое мероприятие. Данные сохраняются на жестком диске или в облачном хранилище и затем забываются. Но в некоторых случаях необходимо иметь возможность повторно использовать собранные данные для анализа, отладки или даже для калибровки последующих измерений. Для этого необходимо разработать механизм воспроизведения данных, который позволяет загружать данные из хранилища и обрабатывать их заново.
Мы используем различные методы хранения данных, такие как CSV, JSON и базы данных. Выбор метода хранения зависит от требований к объему данных, скорости доступа и простоте обработки. Мы также используем различные библиотеки и фреймворки для работы с данными, такие как Pandas, NumPy и SciPy.
Как мы реализуем воспроизведение данных?
Для реализации воспроизведения данных мы создаем специальные скрипты, которые загружают данные из хранилища, обрабатывают их и сохраняют результаты в новом формате. Эти скрипты можно запускать в любое время, чтобы получить новые результаты анализа или для калибровки последующих измерений.
Мы также используем специализированное программное обеспечение для визуализации данных, которое позволяет создавать графики, диаграммы и другие визуальные представления данных. Это помогает нам быстрее и эффективнее анализировать данные и выявлять закономерности.
Но тут тоже не обошлось без сложностей. Иногда возникают проблемы с совместимостью форматов данных. В этих случаях мы приходится разрабатывать специальные конвертеры, которые преобразуют данные из одного формата в другой.
Заключение: сложность и перспективы
Модуль сбора и воспроизведения данных – это не просто набор компонентов, это сложная система, которая требует глубоких знаний и опыта. Мы постоянно совершенствуем наши технологии и разрабатываем новые решения, чтобы повысить точность, надежность и гибкость системы сбора данных. Мы верим, что в будущем модуль сбора и воспроизведения данных будет играть еще более важную роль в различных областях, от науки и техники до медицины и промышленности. И хотя путь к идеальному решению еще долог, мы готовы идти по нему, опираясь на свой опыт и знания. Для ООО Сиань Чэнань Измерение и Контроль Технологии это постоянная работа над собой и постоянное стремление к лучшему.
Соответствующая продукция
Соответствующая продукция



Самые продаваемые продукты
Самые продаваемые продукты-
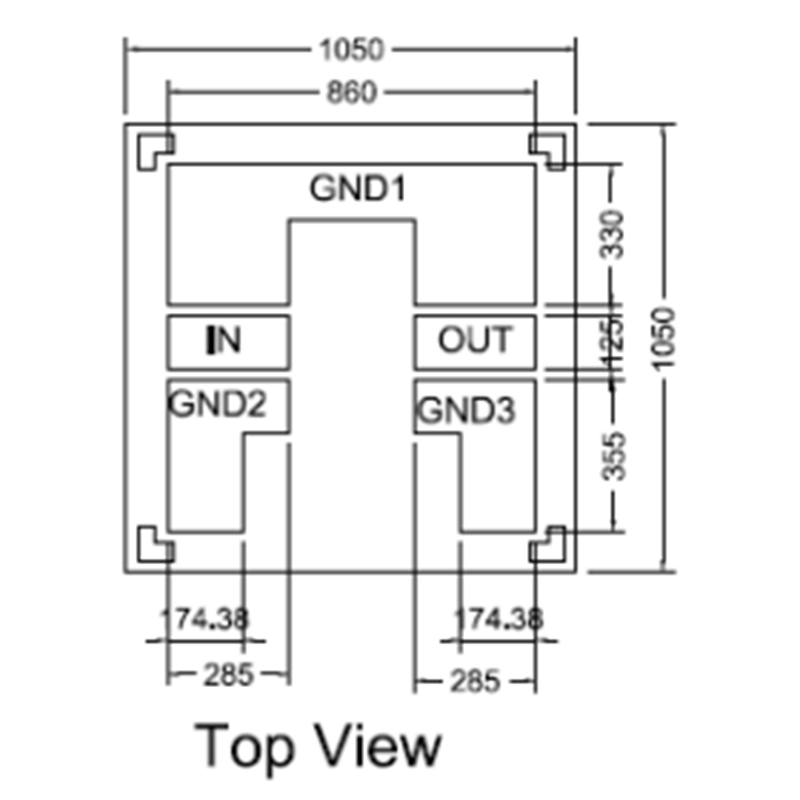
 Оптический преобразователь с дисплейным управлением
Оптический преобразователь с дисплейным управлением -
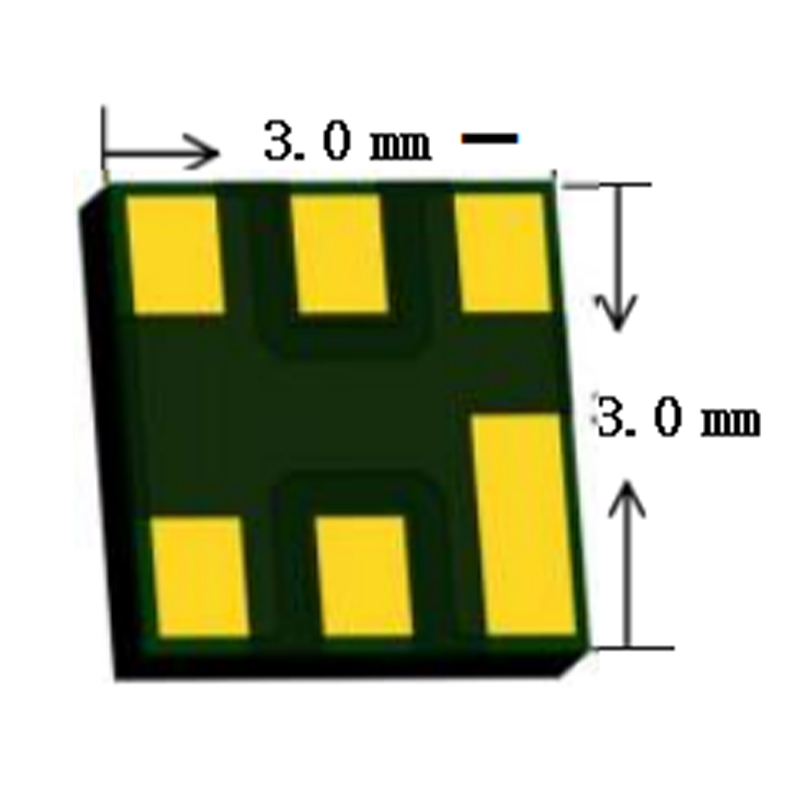
 RSFK1500P000B1 Тонкоплёночный объёмный акустический фильтр
RSFK1500P000B1 Тонкоплёночный объёмный акустический фильтр -
 Датчик давления – Тип B
Датчик давления – Тип B -
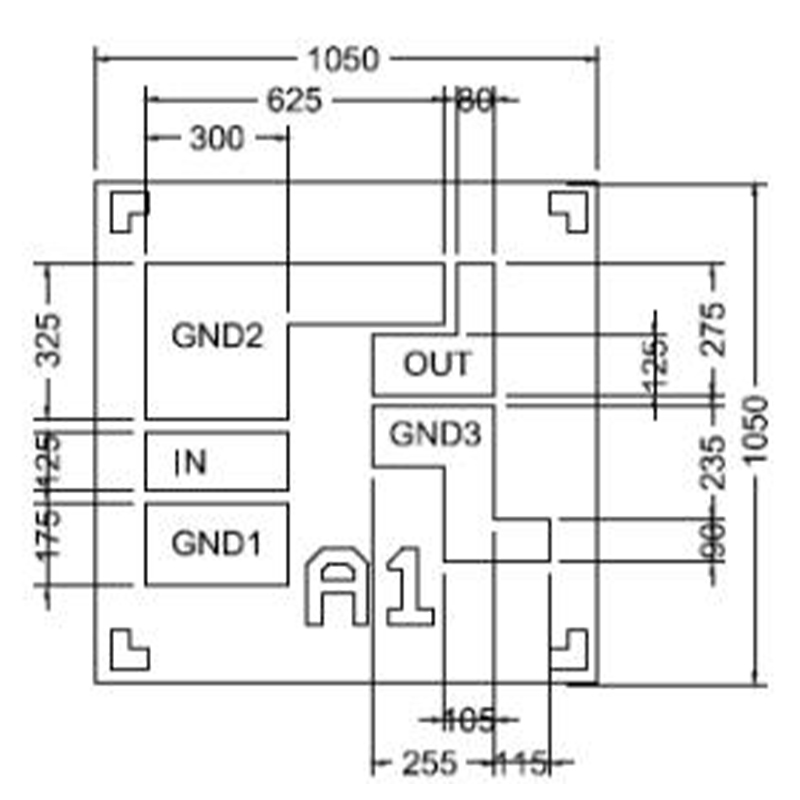
 Модуль обработки сигналов с помехозащитой
Модуль обработки сигналов с помехозащитой -
 Комбинированный датчик температуры и давления – Тип A
Комбинированный датчик температуры и давления – Тип A -
 Радиочастотный силовой транзистор MRF8P29300HR6
Радиочастотный силовой транзистор MRF8P29300HR6 -
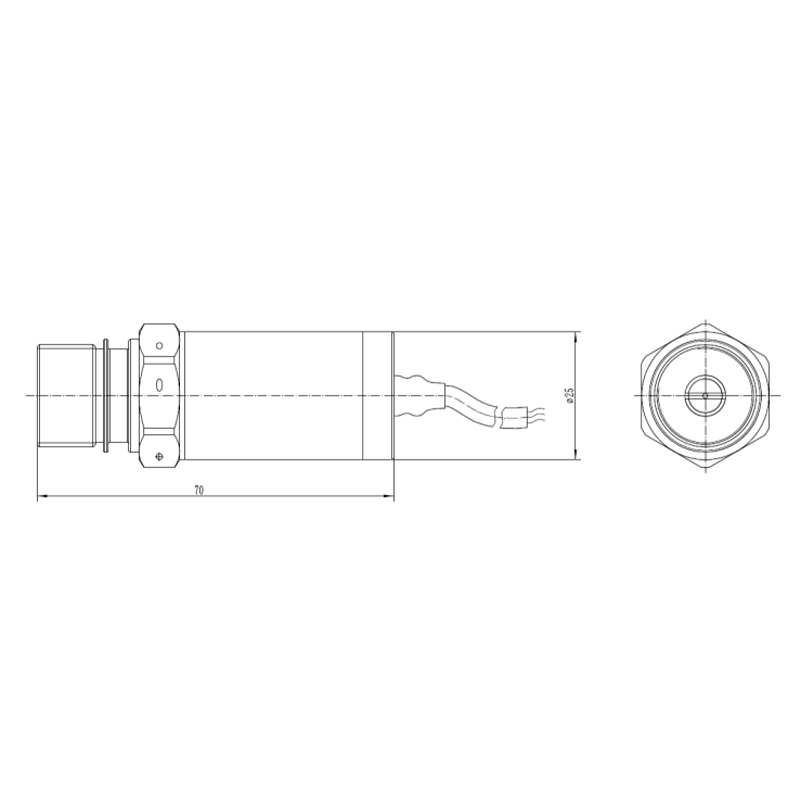 Комбинированный датчик температуры и давления – Тип B
Комбинированный датчик температуры и давления – Тип B -
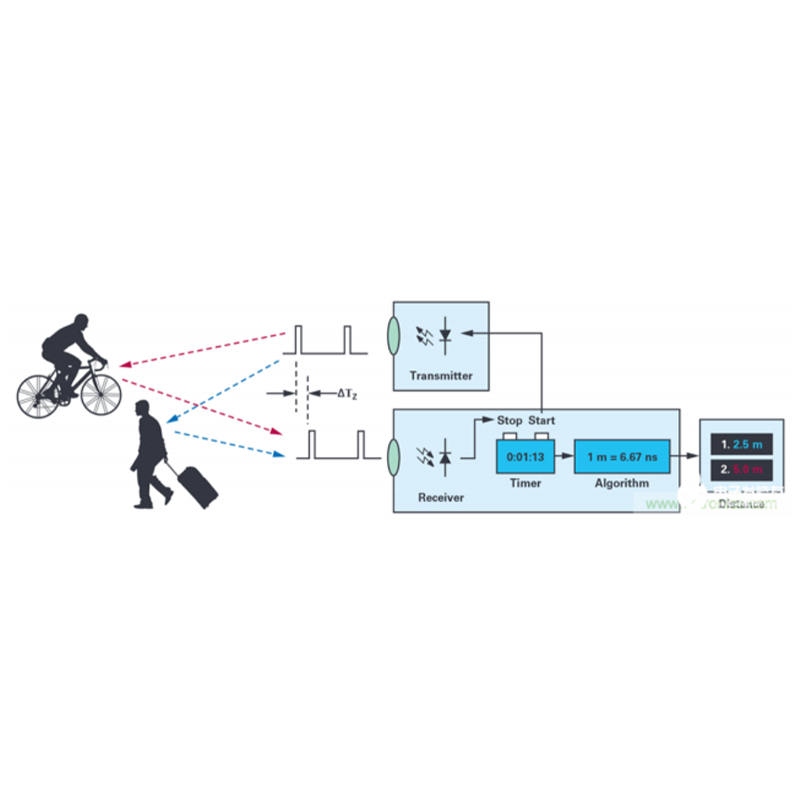 CAMS1205 Высокоточная схема измерения времени для лазерных дальномеров
CAMS1205 Высокоточная схема измерения времени для лазерных дальномеров -
 Комплексный тестер БПЛА
Комплексный тестер БПЛА -
 Чаочжи SiMU9030S инерциальный измерительный модуль
Чаочжи SiMU9030S инерциальный измерительный модуль -
 CAMPS49
CAMPS49 -
 Радиочастотный силовой транзистор AFT31150NR5
Радиочастотный силовой транзистор AFT31150NR5
Связанный поиск
Связанный поиск- Специализированный датчик давления для космических условий производитель
- Интегрированный датчик температуры и давления для интернета вещей завод
- Высокоточный комбинированный датчик температуры и давления производители
- Тактический инерциальный измерительный модуль производитель
- Датчик давления as20h-30 производители
- Датчик давления as20h-350 производитель
- Модуль сбора и воспроизведения рч-сигналов производитель
- Китай датчики избыточного давления цена производитель
- Промышленный комбинированный датчик температуры и давления заводы
- Трёхосевой гироскопический модуль производитель

